
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- sqldeveloper
- 연결
- Linux
- TensorFlow
- oracle
- 파이썬
- psycopg2
- 복구
- GridSearchCV
- 머신러닝
- Python
- pgadmin
- cpu
- docker
- 도커
- 오라클
- psql
- Memory
- 리눅스
- Jupyter
- postgre
- 시계열
- 쿼리
- LOG
- 교차검증
- GPU
- jupyternotebook
- SQL
- 도커이미지
- Docker image
- Today
- Total
areum
[ML] Association Rule Analysis (연관 규칙 분석) 본문
연관 규칙 분석 정의
연관규칙분석(Association Rule Analysis)이란 경영학에서 장바구니 분석(Market Basket Analysis)이라고도 합니다.
A라는 상품을 구매한 후 B상품을 구매했을 때, 서로 연관성이 있다고 하면 A->B라는 일련의 규칙들이 생성되는 알고리즘입니다. 특정 상품 구매 시 이와 연관성 높은 상품을 추천할 수 있습니다.
연관규칙의 평가에는 '지지도, 신뢰도, 향상도' 라는 3가지 척도가 사용됩니다.
지지도(support)
전체 거래 중 A와 B가 동시에 포함된 거래의 확율.

ex) A를 빵, B를 우유라고 하면 빵 -> 버터의 지지도 = ( 빵과 버터를 동시에 구매한 거래 수 ) / ( 전체 거래 수)
신뢰도(confidence)
A를 구매했을 때, 추가로 B를 구매할 확률.

ex) A를 빵, B를 우유라고 하면 빵 -> 버터의 신뢰도 = ( 빵과 버터를 동시에 구매한 거래 수 ) / ( 빵이 포함된 전체 거래 수 )
향상도(lift)
B 상품의 구매 확률이 A상품의 구매에 따라서 얼마나 증가했는지의 확률.
향상도가 1이라는 것은 두 상품의 구매가 독립적이라는 의미. 향상도가 1보다 크다면 A를 구매했을 때 B를 구매할 가능성이 높아지고, 향상도가 1보다 작다면 A를 구매했을 때 B를 구매할 가능성이 낮아지게 된다.

Apriori algorithm 사용하여 분석하기
1. 분석에 필요한 라이브러리들을 불러옵니다.
import pandas as pd
import numpy as np
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules2. 아래는 제가 임의로 만든 데이터셋입니다.
dataset=[['사과','치즈','생수'],
['생수','호두','치즈','고등어'],
['수박','사과','생수'],
['생수','호두','치즈','옥수수']]3. 위 리스트 항목들을 데이터 프레임으로 변경합니다.
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_4. Apriori 알고리즘 활용.
- association_rules 함수를 이용하여 지지도가 0.5가 넘는 항목에 대해 향상도가 양의 상관관계에 있는 것이 무엇인지 알 수 있습니다.
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
association_rules(frequent_itemsets, metric="lift", min_threshold=1)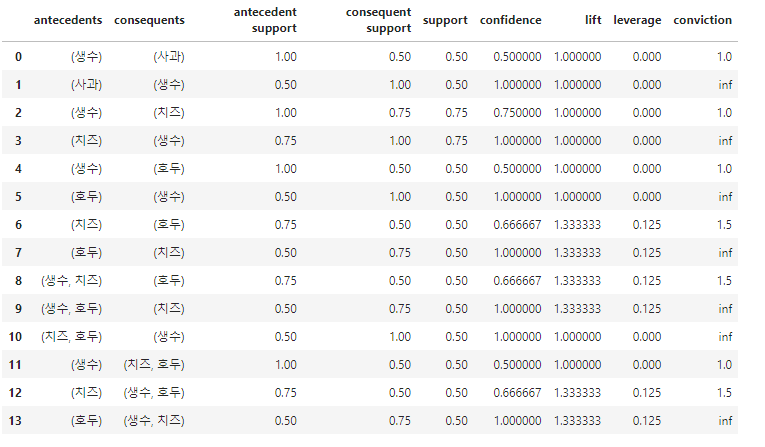
위 예시된 항목으로 보면 생수와 치즈가 양의 상관관계가 있는것으로 확인되어 집니다.
'Programming > Machine Learning' 카테고리의 다른 글
| [ML] LogisticRegression(로지스틱 회귀) (0) | 2023.03.21 |
|---|---|
| [ML] K-Means Clustering (K-평균 군집) (0) | 2023.03.17 |
| [시계열 분석] ARIMA를 이용한 기온 예측 (0) | 2023.01.31 |
| [Machine Learning] GridSearchCV 하이퍼 파라미터 튜닝 (0) | 2022.12.01 |
| [Machine Learning] Random Forest (랜덤포레스트) (0) | 2022.11.30 |


